BERT (Bidirectional Encoder Representations from Transformers) is a new language representation model. BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE score to 80.5%.
Table of contents
- Background
- What makes BERT different?
- RankBrain is not dead. How so?
- Can you optimize for BERT?
- Why we should care?
Background
In the field of computer vision, researchers have repeatedly shown the value of transfer learning — pre-training a neural network model on a known task, for instance ImageNet, and then performing fine-tuning — using the trained neural network as the basis of a new purpose-specific model. In recent years, researchers have been showing that a similar technique can be useful in many natural language tasks.
A different approach, which is also popular in NLP tasks and exemplified in the recent ELMo paper, is feature-based training. In this approach, a pre-trained neural network produces word embedding which are then used as features in NLP models.
It was opened-sourced last year and written about in more detail on the Google AI blog. In short, BERT can help computers understand language a bit more like humans do.
What Makes BERT Different?
BERT builds upon recent work in pre-training contextual representations — including Semi-supervised Sequence Learning, Generative Pre-Training, ELMo, and ULMFit. However, unlike these previous models, BERT is the first deeply bidirectional, unsupervised language representation, pre-trained using only a plain text corpus (in this case, Wikipedia). Why does this matter? Pre-trained representations can either be context-free or contextual, and contextual representations can further be unidirectional or bidirectional. Context-free models such as word2vec or GloVe generate a single word embedding representation for each word in the vocabulary. For example, the word “bank” would have the same context-free representation in “bank account” and “bank of the river.” Contextual models instead generate a representation of each word that is based on the other words in the sentence. For example, in the sentence “I accessed the bank account,” a unidirectional contextual model would represent “bank” based on “I accessed the” but not “account.” However, BERT represents “bank” using both its previous and next context — “I accessed the … account” — starting from the very bottom of a deep neural network, making it deeply bidirectional. A visualization of BERT’s neural network architecture compared to previous state-of-the-art contextual pre-training methods is shown below. The arrows indicate the information flow from one layer to the next. The green boxes at the top indicate the final contextualized representation of each input word:
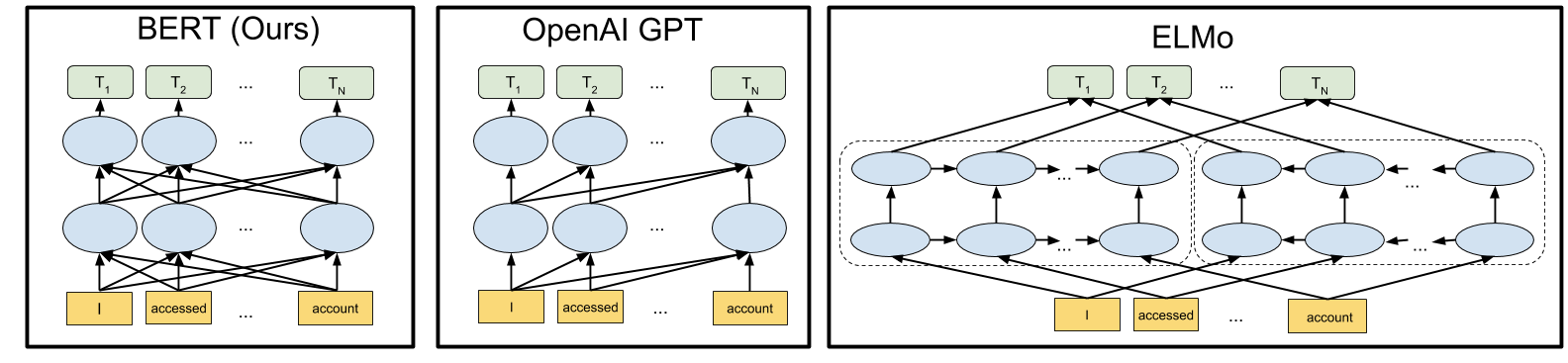 |
| BERT is deeply bidirectional, OpenAI GPT is unidirectional, and ELMo is shallowly bidirectional. |
RankBrain is not dead.
RankBrain was Google’s first artificial intelligence method for understanding queries in 2015. It looks at both queries and the content of web pages in Google’s index to better understand what the meanings of the words are. BERT does not replace RankBrain, it is an additional method for understanding content and queries. It’s additive to Google’s ranking system. RankBrain can and will still be used for some queries. But when Google thinks a query can be better understood with the help of BERT, Google will use that. In fact, a single query can use multiple methods, including BERT, for understanding query.
How so?
Google explained that there are a lot of ways that it can understand what the language in your query means and how it relates to content on the web. For example, if you misspell something, Google’s spelling systems can help find the right word to get you what you need. And/or if you use a word that’s a synonym for the actual word that it’s in relevant documents, Google can match those. BERT is another signal Google uses to understands language. Depending on what you search for, any one or combination of these signals could be more used to understand your query and provide a relevant result.
Can you optimize for BERT?
It is unlikely. Google has told us SEOs can’t really optimize for RankBrain. But it does mean Google is getting better at understanding natural language. Just write content for users, like you always do. This is Google’s efforts at better understand the searcher’s query and matching it better to more relevant results.
Why we should care?
We should, not only because Google said this change is “representing the biggest leap forward in the past five years, and one of the biggest leaps forward in the history of Search.”
But also because 10% of all queries have been impacted by this update. That is a big change. We did see unconfirmed reports of algorithm updates mid-week and earlier this week, which may be related to this change.
We’d recommend you check to see your search traffic changes sometime next week and see how much your site was impacted by this change. If it was, drill deeper into which landing pages were impacted and for which queries. You may notice that those pages didn’t convert and the search traffic Google sent those pages didn’t end up actually being useful.
We will be watching this closely and you can expect more content from us on BERT in the future.